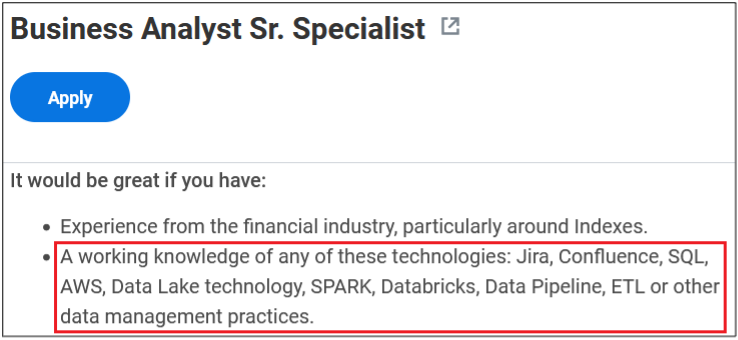
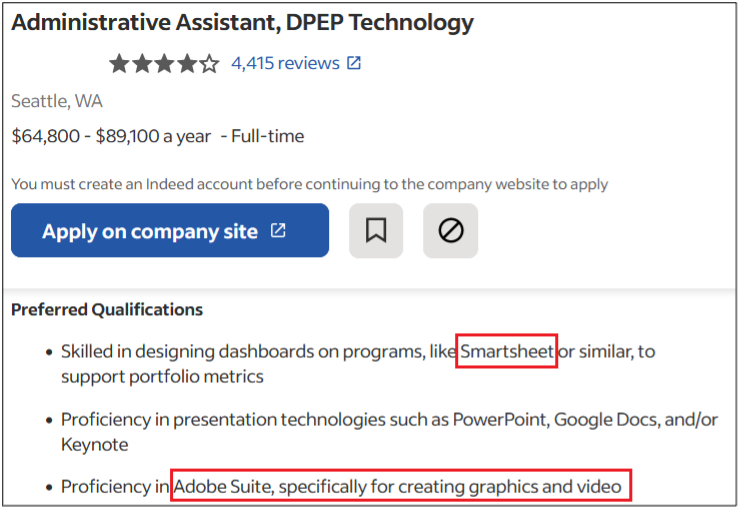
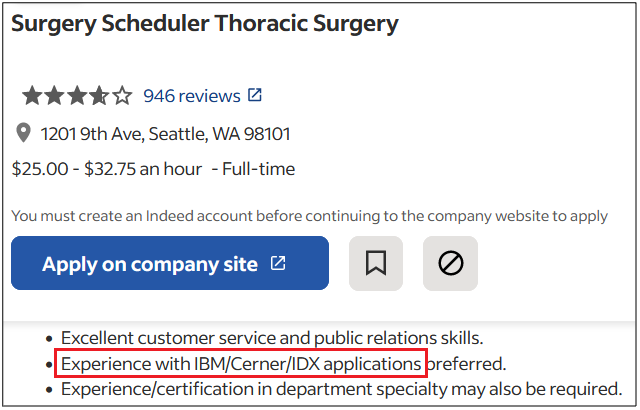
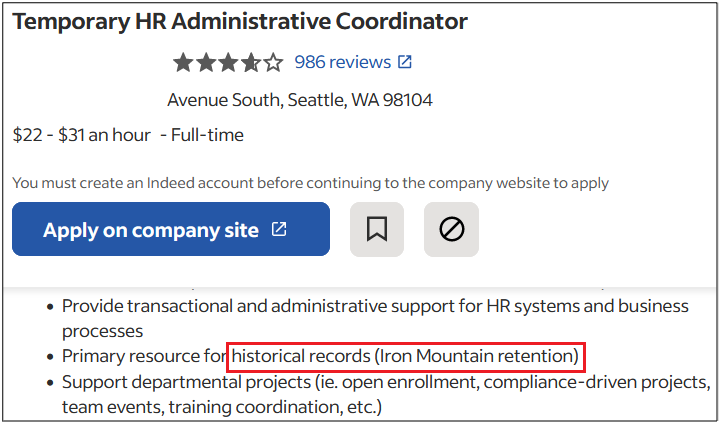
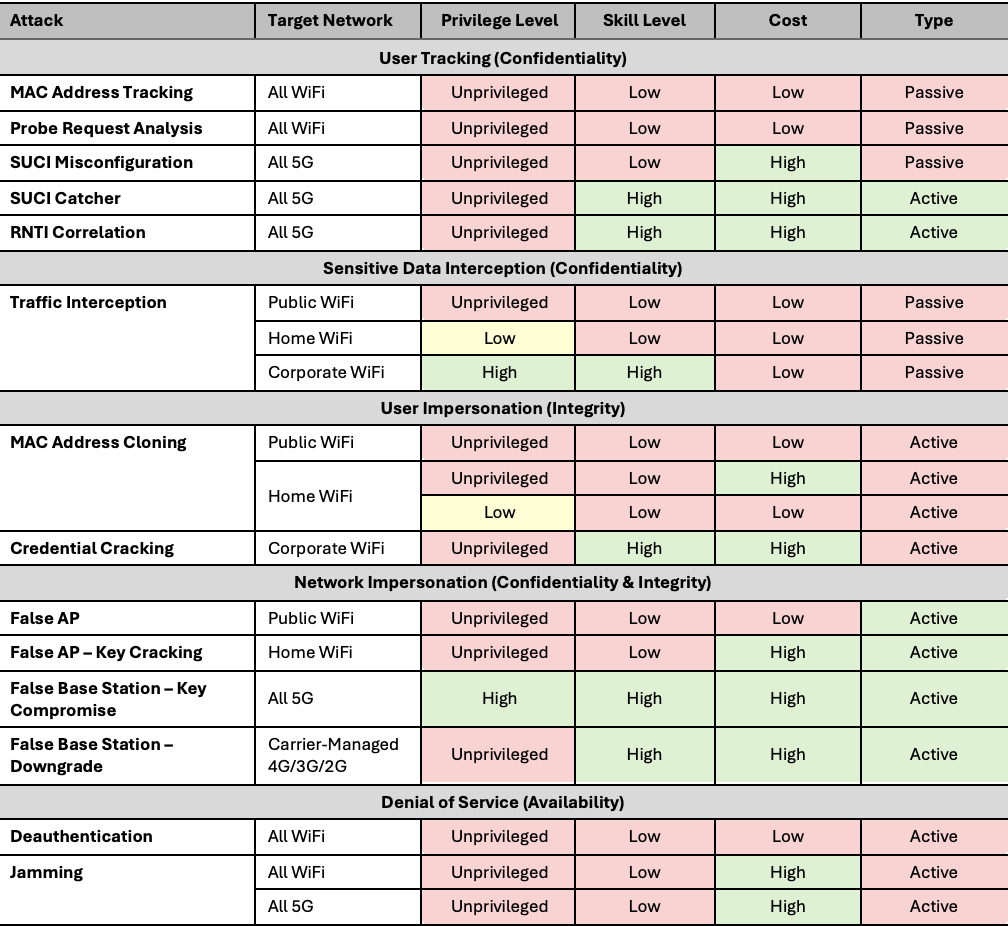
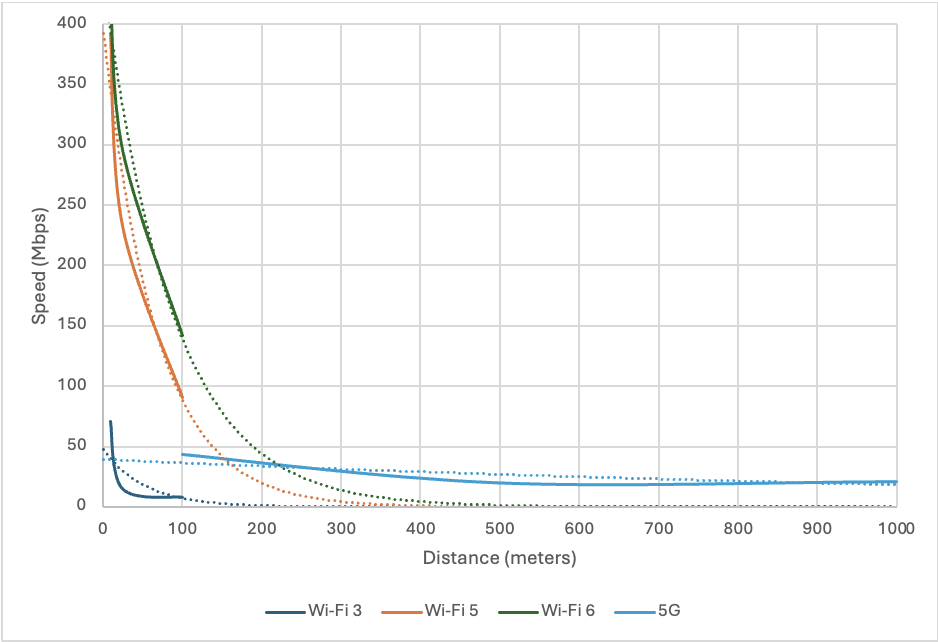
With global cybercrime damage costs exceeding $11 trillion last year and moving toward an estimated $20 trillion by 2026, robust cybersecurity risk management has never been more imperative.
The interconnected nature of modern technology means that, by default, even small vulnerabilities can lead to catastrophic losses. And it’s not just about finances. Unmitigated risk raises the specter of eroded customer confidence and tainted brand reputation. In this comprehensive guide, we’ll give enterprise defenders a holistic, methodical, checklist-style approach to cybersecurity risk management. We’ll focus on practical applications, best practices, and ready-to-implement strategies designed to mitigate risks and safeguard digital assets against ever-more numerous—and increasingly capable—threats and adversaries.
What is Cybersecurity Risk Management?
This subspecialty of enterprise risk management describes a systematic approach to identifying, analyzing, evaluating, and addressing cyber threats to an organization’s assets and operations. At its core, it involves a continuous cycle of risk assessment, risk decision-making, and the implementation of risk controls intended to minimize the negative impact of cyber incidents.
A proactive cyber risk mitigation approach helps organizations protect critical digital assets and bolster business continuity, legal compliance, and customer trust. By integrating risk management with the organization’s overall strategic planning, cybersecurity teams can prioritize resources efficiently and align their efforts with the business’s risk appetite and objectives.
Why Has Cyber Risk Management Become So Critical?
Getting control over cyber risk is quickly becoming a core requirement for businesses operating in today’s digital ubiquity. The proliferation of digital information and internet connectivity have paved the way for sophisticated cyber threats that can penetrate many of our most robust defenses. With the digital footprint of businesses expanding exponentially, the potential for data breaches, ransomware attacks, and other forms of cybercrime has escalated dramatically.
These incidents can result in devastating financial losses, legal repercussions, and irreparable damage to an organization’s reputation. Furthermore, as regulatory frameworks around data protection become more stringent, failure to comply can lead to significant penalties. Given these conditions, an aggressive and comprehensive approach to managing cybersecurity risks is crucial for safeguarding an organization’s assets, ensuring operational continuity, and maintaining trust with customers and stakeholders.
Effective Cyber Risk Management: A Framework-Based Approach
Adopting a structured, framework-based approach to cybersecurity risk management lets security teams corral the complexity of digital environments with a methodical, strategic mitigation methodology. For most enterprise applications, there’s no need to reinvent the wheel. There are a myriad of established frameworks that can be modified and customized for effective use in nearly any environment.
Perhaps the best known is the National Institute of Standards and Technology (NIST) Risk Management Framework (RMF), a companion to NIST’s well-tested and widely implemented Cybersecurity Framework (CSF). The NIST RMF offers a structured and systematic approach for integrating security, privacy, and risk management processes into an organization’s system development life cycle.
Such frameworks provide a comprehensive set of guidelines that help identify and assess cyber threats and facilitate the development of effective strategies to mitigate these risks. By standardizing cybersecurity practices, organizations can ensure a consistent and disciplined application of security measures across all departments and operations.
This coherence and uniformity are crucial for effectively addressing vulnerabilities and responding to incidents promptly. Equally important, frameworks incorporate best practices and benchmarks that help guide organizations toward achieving compliance with regulatory requirements, thus minimizing legal risks and enhancing the safeguarding of customer data. In essence, a framework-based approach offers a clear roadmap for managing cyber risk in a way that’s aligned with organizational strategic objectives and industry standards.
What follows is a checklist based on the 7-step RMF process. This is just a starting point. A framework to-do list like this can and should be tweaked to aid in reducing and managing specific cyber risks in your unique enterprise environment.
1. Preparation
In this initial phase, organizations focus on establishing the context and priorities for the Risk Management Framework process. This involves identifying critical assets, defining the boundaries, and codifying a risk management strategy that aligns with the organization’s objectives and resources. This is the foundation upon which a tailored approach to managing cybersecurity risk will ultimately be built throughout the system’s lifecycle.
- Establish the context for risk management and create a risk management strategy.
- Define roles and responsibilities across the organization.
- Develop a taxonomy for categorizing information and information systems.
- Determine the legal, regulatory, and contractual obligations.
- Prepare an inventory of system elements, including software and hardware.
2. Systems Categorization
Expanding on the categorization step (above), this phase involves identifying the types of information processed, stored, and transmitted to determine potential impact as measured against the information security CIA triad (confidentiality, integrity, and availability). Organizations can assign appropriate security categories to their systems by leveraging a categorization standard such as the Federal Information Processing Standard (FIPS) 199, ensuring that the protective measures taken are tailored to the specific needs and risks associated with the information being handled. This step is crucial as it lays the groundwork for selecting suitable security controls in the later stages of the risk management process.
- Identify the types of information processed, stored, and transmitted by the system.
- Assess the potential impact of loss of Confidentiality, Integrity, and Availability (CIA) associated with each type.
- Document findings in a formal security categorization statement.
3. Selecting Appropriate Security Controls
This critical step begins the safeguarding of information systems against potential threats and vulnerabilities in earnest. Based on the categorization of the information system, organizations select a baseline of security and privacy controls (NIST Special Publication 800-53 or some equivalent controls standard is a good starting point here), corresponding to the system’s impact level. This baseline acts as the jumping-off point for the security controls, which can be tailored to address the specific risks identified throughout the risk assessment process. Customization involves adding, removing, or modifying controls to ensure a robust defense tailored to the unique requirements and challenges of the organization.
- Select an appropriate baseline of security controls (NIST SP 800-53 or equivalent).
- Tailor the baseline controls to address specific organizational needs and identified risks.
- Document the selected security controls in the system security plan.
- Develop a strategy for continuously monitoring and maintaining the effectiveness of security controls.
4. Implementing the Selected Controls
Implementing security controls involves the physical and technical application of measures chosen during the previous selection phase. This step requires careful execution to ensure all controls are integrated effectively within the environment, aligning with its architecture and operational practices. Documenting the implementation details is crucial to provide a reference for future assessments and maintenance activities.
- Implement the security controls as documented in Step 3.
- Document the security controls and the responsible entities in place.
- Test thoroughly to ensure compatibility and uninterrupted functionality.
- Prepare for security assessment by documenting the implementation details.
5. Assessing Controls Performance
Assessing security controls involves evaluating effectiveness and adherence to the security requirements outlined in the overall security plan. This phase is critical for identifying any control deficiencies or weaknesses that could leave the information system vulnerable. Independent reviewers or auditors typically conduct assessments to ensure objectivity and a comprehensive analysis.
- Develop and implement a plan to assess the security controls.
- Perform security control assessments as per the plan.
- Prepare a Security Assessment Report (SAR) detailing the effectiveness of the controls.
- Determine if additional controls are needed and append the master security plan accordingly.
6. Authorizing the Risk Management Program
The authorization phase is a vital decision-making interval where one or more senior executives evaluate the security controls’ assessment results and decide whether the remaining risks to the information systems are acceptable to the organization. Upon acceptance, authorization is granted to operate the mitigation program for a specific time period, during which its compliance and security posture are continuously monitored. This authorization is formalized through the issuance of what is known as an Authorization to Operate (ATO) in some organizations, particularly in the public sector.
- Compile the required authorization package, including the master plan, the SAR, and the so-called Plan of Action and Milestones (POA&M).
- Assess the residual risk against the organizational risk tolerance.
- Document the authorization decision in an Authorization Decision Document.
7. Monitoring and Measuring Against Performance Metrics
The monitoring phase ensures that all implemented security controls remain effective and compliant over time. Continuous surveillance, reporting, and analysis can promptly address any identified vulnerabilities or changes in the operational environment. This ongoing process supports the kind of flexible, adaptive security posture necessary for dealing with evolving threats while steadfastly maintaining the integrity and availability of the information system.
- Implement the plan for ongoing monitoring of security controls.
- Report the system’s security state to designated leaders in the organization.
- Perform ongoing risk assessments and response actions, updating documentation as necessary.
- Conduct reviews and updates regularly, in accordance with the organizational timelines, or as significant changes occur.
Conclusion: Formalizing Cyber Risk Mitigation
A solid risk management framework provides a comprehensive guide for enhancing the security and resilience of information systems through a structured process of identifying, implementing, and monitoring security controls.
Sticking to a framework checklist helps ensure a successful, systematic adoption. As noted throughout, engaging stakeholders from across the organization, including IT, security, operations, and compliance, is critical to ensuring a truly comprehensive risk management program. Additionally, periodic training and awareness for team members involved in various phases of the risk management project will contribute to the resilience and security of the organization’s digital assets.
Organizations can effectively safeguard their digital assets and mitigate unacceptable risks by following the outlined steps, tailoring the program to fit specific organizational needs, involving stakeholders, conducting regular training, and adapting to the evolving cybersecurity landscape. Ultimately, this kind of formal, structured cyber risk management fosters a culture of continuous improvement and vigilance in an enterprise, contributing to the overall security posture and the success of the organization.