Disclaimer: No businesses or even the Internet were harmed while researching this post. We will explore how an attacker can control the Internet access of one or more ISPs or countries through ordinary routers and Internet modems.
Cyber-attacks are hardly new in 2013. But what if an attack is both incredibly easy to construct and yet persistent enough to shut Internet services down for a few hours or even days? In this blog post we will talk about how easy it would be to enlist ordinary home Internet connections in this kind of attack, and then we suggest some potentially straightforward solutions to this problem.
The first problem
The Internet in the last 10 to 20 years has become the most pervasive way to communicate and share news on the planet. Today even people who are not at all technical and who do not love technology still use their computers and Internet-connected devices to share pictures, news, and almost everything else imaginable with friends and acquaintances.
All of these computers and devices are connected via CPEs (customer premises equipment) such as routers, modems, and set-top boxes etc. that enable consumers to connect to the Internet. Although most people consider these CPEs to be little magic boxes that do not need any sort of provisioning, in fact these plug-and-play devices are a key, yet weak link behind many major attacks occurring across the web today.
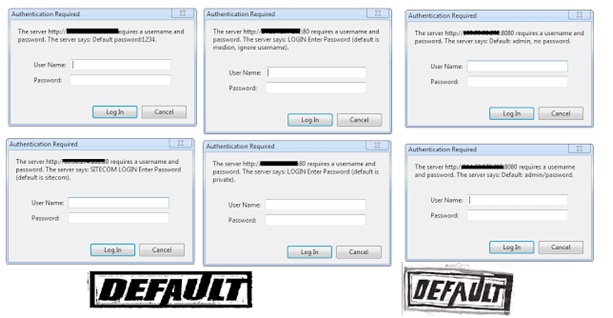
These little magic boxes come with some nifty default features:
- Updateable firmware.
- Default passwords.
- Port forwarding.
- Accessibility over http or telnet.
The second problem
All ISPs across the world share a common flaw. Look at the following screen shot and think about how one might leverage this flaw.
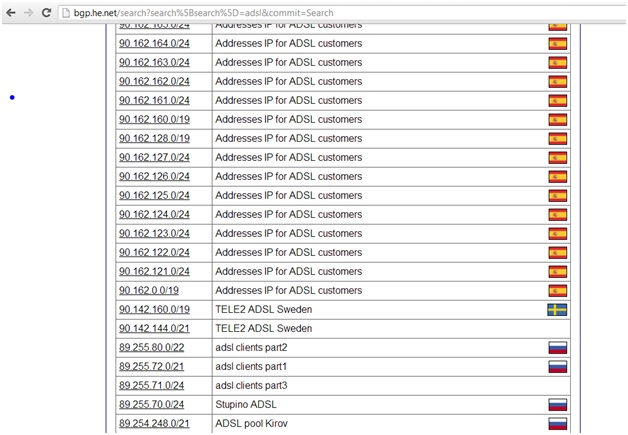
Most ISPs that own one or more netblocks typically write meaningful descriptions that provide some insight into what they are used for.
Attack phase 1
So what could an attacker do with this data?
- They can gather a lot of information about netblocks for one or more ISPs and even countries and some information about their use from http://bgp.he.net and http://ipinfodb.com.
- Next, they can use whois or parse bgp.he.net to search for additional information about these netblocks, such as data about ADSL, DSL, Wi-Fi, Internet users, and so on.
- Finally, the attacker can convert the matched netblocks into IP addresses.
At this point the attacker could have:
- Identified netblocks for an entire ISP or country.
- Pinpointed a lot of ADSL networks, so they have minimized the effort required to scan the entire Internet. With a database gathered and sorted by ISP and country an attacker can, if they wanted to, control a specific ISP or country.
Next the attacker can test how many CPEs he can identify in a short space of time to see whether this attack would be worth pursuing:
A few hours later the results are in:
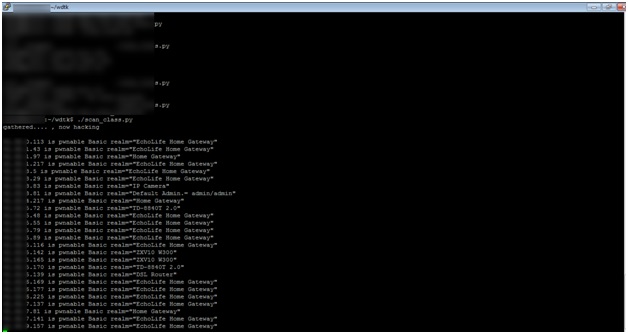
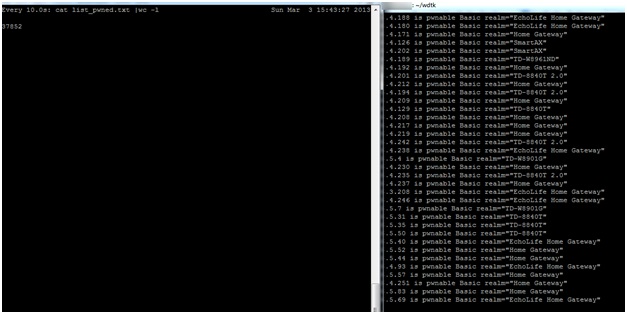
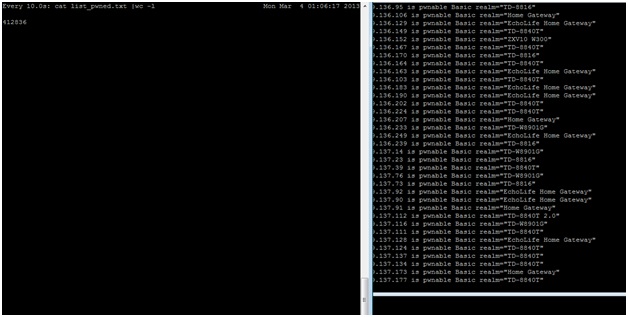
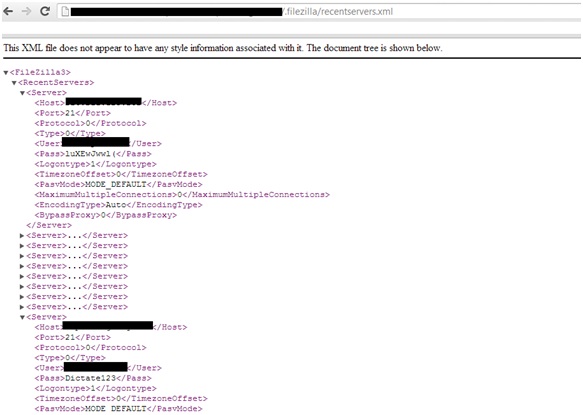
In this case the attacker has identified more than 400,000 CPEs that are potentially vulnerable to the simplest of attacks, which is to scan the CPEs using both telnet and http for their default passwords.
We can illustrate the attacker’s plan with a simple diagram:
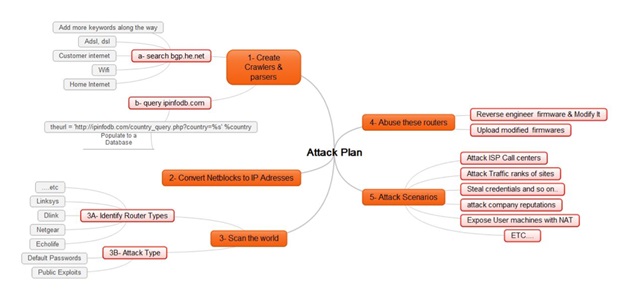
Attack Phase 2 (Command Persistence)
Widely available tools such as binwalk, firmware-mod-kit, and unix dd make it possible to modify firmware and gain persistent control over CPEs. And obtaining firmware for routers is relatively easy. There are several options:
- The router is supported by dd-wrt (http://dd-wrt.com)
- The attacker either works at an ISP or has a friend who works at an ISP and happens to have easy access to assorted firmware.
- Search engines and dorks.
As soon as the attacker is comfortable with his reverse-engineered and modified firmware he can categorize them by CPE model and match them to the realm received from the CPE under attack. In fact with a bit of tinkering an attacker can automate this process completely, including the ability to upload the new firmware to the CPEs he has targeted. Once installed, even a factory reset will not remove his control over that CPE.
The firmware modifications that would be of value to attacker include but are not limited to the following:
- Hardcoded DNS servers.
- New IP table rules that work well on dd-wrt-supported CPEs.
- Remove the Upload New Firmware page.
CPE attack phase recap
- An attacker gathers a country’s netblocks.
- He filters ADSL networks.
- He reverse engineers and modifies firmware.
- He scans ranges and uploads the modified firmware to targeted CPEs.
Follow-up attack scenarios
If an attacker is able to successfully compromise a large number of CPEs with the relatively simple attack described above, what can he do for a follow-up?
- ISP attack: Let’s say an ISP has a large number of IP addresses vulnerable to the CPE compromise attack and an attacker modifies the firmware settings on all the ADSL routers on one or more of the ISP’s netblocks. Most ISP customers are not technical, so when their router is unable to connect to the Internet the first thing they will do is contact the ISP’s Call Center. Will the Call Center be able to handle the sudden spike in the number of calls? How many customers will be left on hold? And what if this happens every day for a week, two weeks or even a month? And if the firmware on these CPEs is unfixable through the Help Desk, they may have to replace all of the damaged CPEs, which becomes an extremely costly affair for the company.
- Controlling traffic: If an attacker controls a huge number of CPEs and their DNS settings, being able to manipulate website traffic rankings will be quite trivial. The attacker can also redirect traffic that was supposed to go to a certain site or search engine to another site or search engine or anywhere else that comes to mind. (And as suggested before, the attacker can shut down the Internet for all of these users for a very long time.)
- Company reputations: An attacker can post:
-
- False news on cloned websites.
- A fake marketing campaign on an organization’s website.
- Make money: An attacker can redirect all traffic from the compromised CPEs to his ads and make money from the resulting impressions. An attacker can also add auto-clickers to his attack to further enhance his revenue potential.
- Exposing machines behind NAT: An attacker can take it a step further by using port forwarding to expose all PCs behind a router, which would further increase the attack’s potential impact from CPEs to the computers connected to those CPEs.
- Launch DDoS attacks: Since the attacker can control traffic from thousands of CPEs to the Internet he can direct large amounts of traffic at a desired victim as part of a DDoS attack.
- Attack ISP service management engines, Radius, and LDAP: Every time a CPE is restarted a new session is requested; if an attacker can harvest enough of an ISP’s CPEs he can cause Radius, LDAP and other ISP services to fail.
- Disconnect a country from the Internet: If a country’s ISPs do not protect against the kind of attack we have described an entire country could be disconnected from the Internet until the problem is resolved.
- Stealing credentials: This is nothing new. If DNS records are totally in the control of an attacker, they can clone a few key social networking or banking sites and from there they could steal all the credentials he or she wants.
In the end it would be almost impossible to take back control of all the CPEs that were compromised through the attack strategies described above. The only way an ISP could recover from this kind of incident would be to make all their subscribers buy new modems or routers, or alternatively provide them with new ones.
Solutions
There are two solutions to this problem. This involves fixes from CPE vendors and also from the ISPs.
Vendor solution:
Vendors should stop releasing CPEs that have only rudimentary and superficial default passwords. When a router is being installed on a user’s premises the user should be required to change the administrator password to a random value before the CPE becomes fully functional.
ISP solutions:
Let’s look at a normal flow of how a user receives his IP address from an ISP:
- The subscriber turns on his home router or modem, which sends an authentication request to the ISP.
- ISP network devices handle the request and forwards it to Radius to check the authentication data.
- The Radius Server sends Access-Accept or Access-Reject messages back to the network device.
- If the Access-Accept message is valid, DHCP assigns an IP to the subscriber and the subscriber is now able to access the Internet.
However, this is how we think this process should change:
- Before the subscriber receives an IP from DHCP the ISP should check the settings on the CPE.
- If the router or modem is using the default settings, the ISP should continue to block the subscriber from accessing the Internet. Instead of allowing access, the ISP should redirect the subscriber to a web page with a message “You May Be At Risk: Consult your manual and update your device or call our help desk to assist you.”
- Another way of doing this on the ISP side is to deny access from the Broadband Remote Access Server (BRAS) routers that are at the customer’s edge; an ACL could deny some incoming ports, but not limited to 80,443,23,21,8000,8080, and so on.
- ISPs on international gateways should deny access to the above ports from the Internet to their ADSL ranges.
Detecting attacks
ISPs should be detecting these types of attacks. Rather than placing sensors all over the ISP’s network, the simplest way to detect attacks and grab evidence is to lure such attackers into a honeypot. Sensors would be a waste of money and require too much administrative overhead, so let’s focus on one server:
1- Take a few unused ADSL subnets /24
x.x.x.0/24
x.x.y.0/24 and so on
2- Configure the server to be a sensor:
A simple telnet server and a simple Apache server with htpasswd setup as admin admin on the web server’s root directory would suffice.
3- On the router that sits before the servers configure static routes with settings that look something like this:
route x.x.x.0/24 next-hop <server-ip>;
route x.x.y.0/24 next-hop <server-ip>;
route x.x.z.0/24 next-hop <server-ip>;
4- After that you should redistribute your static routes to advertise them on BGP so when anyone scans or connects to any IP in the above subnets they will be redirected to your server.
5- On the server side (it should probably be a linux server) the following could be applied (in the iptables rules):
iptables -t nat -A PREROUTING -p tcp -d x.x.x.0/24 –dport 23 -j DNAT –to <server-ip>:24
iptables -t nat -A PREROUTING -p tcp -d x.x.y.0/24 –dport 23 -j DNAT –to <server-ip>:24
iptables -t nat -A PREROUTING -p tcp -d x.x.z.0/24 –dport 23 -j DNAT –to <server-ip>:24
6- Configure the server’s honeypot to listen on port 24; the logs can be set to track the x.x.(x|y|z).0/24 subnets instead of the server.
Conclusion
The Internet is about traffic from a source to a destination and most of it is generated by users. If users cannot reach their destination then the Internet is useless. ISPs should make sure that end users are secure and users should demand ISPs to implement rules to keep them secure. At the same time, vendors should come up with a way to securely provision their CPEs before they are connected to the Internet by forcing owners to create non-dictionary/random usernames or passwords for these devices.