At IOActive Labs, I have the privilege of being part of a great team with some of the world’s best hackers. I also have access to really cool research on different technologies that uncovers security problems affecting widely used hardware and software. This gives me a solid understanding of the state of security for many different software and hardware devices, not just opinions based on theories and real life experience.
Currently, the term Internet-of-Things (IoT) is becoming a buzzword used in the media, announcements from hardware device manufacturers, etc. Basically, it’s used to describe an Internet with everything connected to it. It describes what we are seeing nowadays, including:
- Laptops, tablets, smartphones, set-top boxes, media-streaming devices, and data-storage devices
- Watches, glasses, and clothes
- Home appliances, home switches, home alarm systems, home cameras, and light bulbs
- Industrial devices and industrial control systems
- Cars, buses, trains, planes, and ships
- Medical devices and health systems
- Traffic sensors, seismic sensors, pollution sensors, and weather sensors
…and more; you name it, and it is or soon will be connected to the Internet.
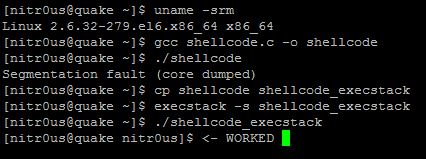
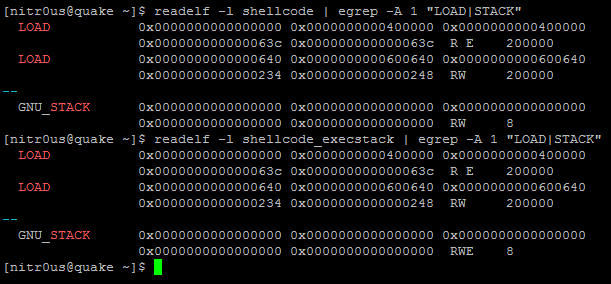
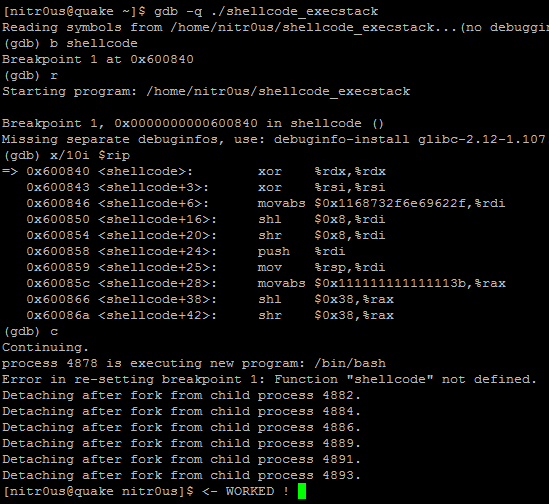
While the devices and systems connected to the Internet are different, they have something in common–most of them suffer from serious security vulnerabilities. This is not a guess. It is based on IOActive Labs’ security research into many of these types of devices currently being used worldwide. Sadly, we are seeing almost the exact same vulnerabilities on these devices that have plagued software vendors over the last decade. Vulnerabilities that the most important software vendors are trying hard to eradicate. It seems that many hardware companies are following really poor security practices when adding software to their products and connecting them to the Internet. What is worse is that sometimes vendors don’t even respond to security vulnerability reports or just downplay the threat and don’t fix the vulnerabilities. Many vendors don’t even know how to properly deal with the security vulnerabilities being reported.
Some of common vulnerabilities IOActive Labs finds include:
- Sensitive data sent over insecure channels
- Improper use of encryption
- No SSL certificate validation
- Things like encryption keys and signing certificates easily available to anyone
- Hardcoded credentials/backdoor accounts
- Lack of authentication and/or authorization
- Storage of sensitive data in clear text
- Unauthenticated and/or unauthorized firmware updates
- Lack of firmware integrity check during updates
- Use of insecure custom made protocols
Also, data ambition is working against vendors and is increasing attack surfaces considerably. For example, all data collected is sent to “vendor cloud” and device commands are sent from “vendor cloud”, instead of just allowing users to connect directly to and command their devices. Hacking into “vendor cloud” = thousands of devices compromised = lots of lost money.
Why should we worry about all of this? Well, these devices affect our everyday life and will continue to do so more and more. We’ve only seen the tip of the iceberg when it comes to the attacks that people, companies, and governments face and how easily they can be performed. If the situation doesn’t change soon, it is just matter of time before we witness attacks with tragic consequences.
If a headline like “+100K Digital Toilets from XYZ1.3 Inc. Found Sending Spam and Distributing Malware” doesn’t scare you because you think it’s funny and improbable, you could be wrong. We shouldn’t wait for headlines such as “Dozens of People Injured When Home Automation Devices Hacked” before we react.
Something must be done! From enforcing secure practices during product development to imposing high fines when products are hacked, action must be taken to prevent the loss of money and possibly even lives.
Companies should strongly consider:
-
- Training developers on secure development
- Implementing security development practices to improve software security
- Training company staff on security best practices
- Implementing a security patch development and distribution process
- Performing product design/architecture security reviews
- Performing source code security audits
- Performing product penetration tests
- Performing company network penetration tests
- Staying up-to-date with new security threats
- Creating a bug bounty program to reward reported vulnerabilities and clearly defining how vulnerabilities should be reported
- Implementing a security incident/emergency response team
It is difficult to give advice to end users given that the best solution is just not to buy or use many products because they are insecure by design. At this stage, it’s just matter of being lucky and hoping that you won’t be hacked. Maybe opportunistic vendors could come up with some novel solution such as an IPS/anti* device that will protect all of your devices from attacks. Just pray that the protection device itself is not vulnerable.
Sometimes end users are forced to live with insecure devices since there isn’t any way to turn them off or not to use them. These include devices provided by TV cable companies, electricity and gas companies, public services companies, governments, etc. These companies and the government should take responsibility for deploying secure products.
This is not BS–in a couple of days we will be releasing some of the extensive research I mentioned and on which this blog post is based.
I intend for this post to be a wakeup call for everyone! I’m really concerned about the current situation. In the meantime, I will use the term INTERNET-of-THREATS (not Internet-of-Things). Maybe this new buzzword will make us more conscious of the situation. If it doesn’t, then at least I have tried.